GPT-4o、Gemini 这些顶级语音模型虽然展现了惊人的共情对话能力博牛配资,但它们的技术体系完全闭源。
现在,紫东太初团队联合长城汽车 AI Lab 直接把整个技术栈都开源了,推出完全透明开源的端到端共情语音语言大模型 OpenS2S。

OpenS2S 的核心在于提供一个高效、低成本构建共情语音系统的新范式。
它不仅继承了团队在语音到文本共情模型 BLSP-Emo 上的技术积累,更引入了流式交错解码架构,实现了低延迟的实时语音生成。OpenS2S 提出自动化数据生成方法,结合大语言模型与可控文本到语音生成技术,构建多说话者、多情感的高质量共情语音训练语料。
最为重要的是,团队开源了构建 OpenS2S 所需的所有资源,包括:训练与微调数据集、数据构建代码、模型权重以及预训练和微调代码,致力于赋能更广泛的研究社区,推动共情语音系统领域的创新与发展。

△表 1 语音语言大模型的开源程度核心贡献
1. 模型的构建与训练
OpenS2S 基于先进的框架构建了高效的端到端语音到语音共情对话模型,并使用高质量数据进行训练。该模型能够为人类与人工智能提供更便捷、更自然的交互方式。
2. 共情语音指令数据集的自动化构建
OpenS2S 提出了一种自动化的数据增强方法,融合了大语言模型(LLMs)与文本到语音(TTS)技术的优势,专为共情语音对话而设计。借助 LLMs 生成丰富多样的用户提问与共情回应,再通过语音克隆技术确保说话者身份的多样性。更重要的是,该技术实现了对语音情感表达的精准控制,能够以极低的人力成本,构建出内容丰富、高质量的训练数据集,为共情语音系统的发展注入强大动力。
3. 全面开源发布
为促进学术合作与推动共情大规模语音语言模型(LSLMs)领域的快速创新,OpenS2S 完整开源了所有核心资源。包括模型权重、数据集构建代码、预训练与微调代码、评估工具及合成数据集,致力于为研究社区提供完全透明、可复现的研究基础,助力共情语音技术的持续突破。
技术方案
OpenS2S 采用模块化设计,包含四大核心组件:
- 音频编码器:基于 Qwen2-Audio 编码器,高效提取音频波形中的语义与非语言特征。
- 指令遵循大语言模型(LLM):选用 Qwen3-8B-Instruct,发挥其强大的文本理解与处理能力,实现精准指令解析。
- 流式语音解码器:借鉴 Minmo 与 LLaMA-Omni2博牛配资,采用监督语义语音分词器将语音响应离散化为 token,随后通过自回归文本到语音模型生成连续语音 token,实现低延迟流式生成。
- Token2Wav 解码器:将生成的语音 token 转换为最终语音波形,分块感知因果流匹配模型及 HiFi-GAN 声码器均采用 GLM-4-Voice 中的预训练组件,保证语音质量自然流畅。
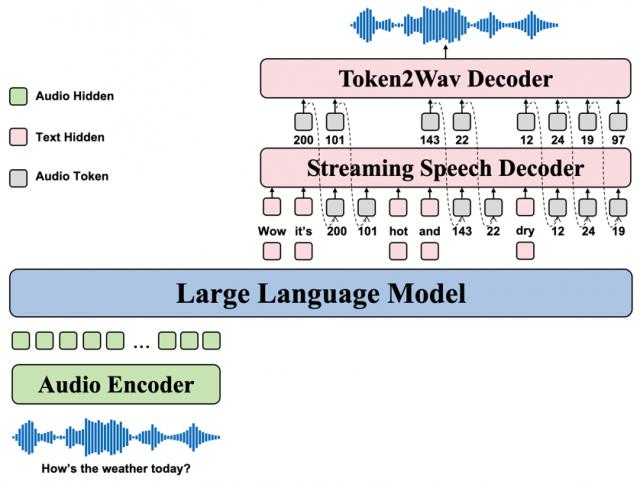
** △图 1 OpenS2S 架构示意图
数据构建过程:
首先,利用强大的 LLMs 生成多样化且富有共情色彩的用户查询及其对应的回应,确保了对话内容的丰富性和真实性。
接着,通过引入语音克隆技术,进一步丰富了数据集的语音多样性,使其能够模拟不同说话者的声音。
更进一步,借助 InstructTTS 技术,模型能够对语音回应中的情感表达进行精确控制,使合成的语音不仅语义连贯,更能在情感层面自然地传递共情。
通过这一自动化流程,OpenS2S 实现了以极低的成本合成出大量高质量、具备语言多样性的共情语音对话数据,并且仅需少量人工监督,从而为模型学习富有共情的人机交互提供了坚实且可扩展的训练基础。
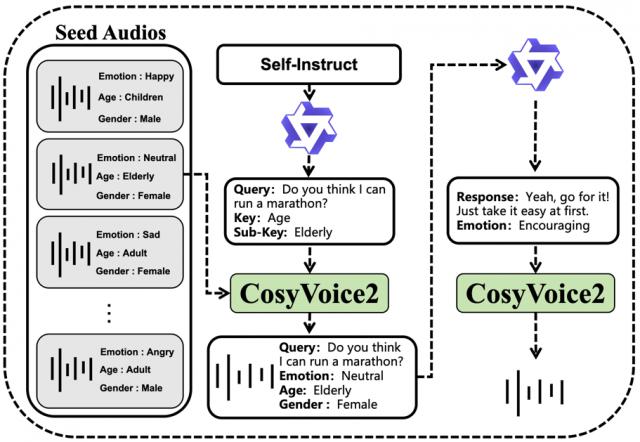
△图 2 共情语音指令数据集构建的自动化流程
训练流程分为三阶段:
语音理解预训练、语音生成预训练及共情语音指令微调,全面提升模型对语音语义和非语言线索的感知能力,最终实现自然且富有共情的语音响应生成。
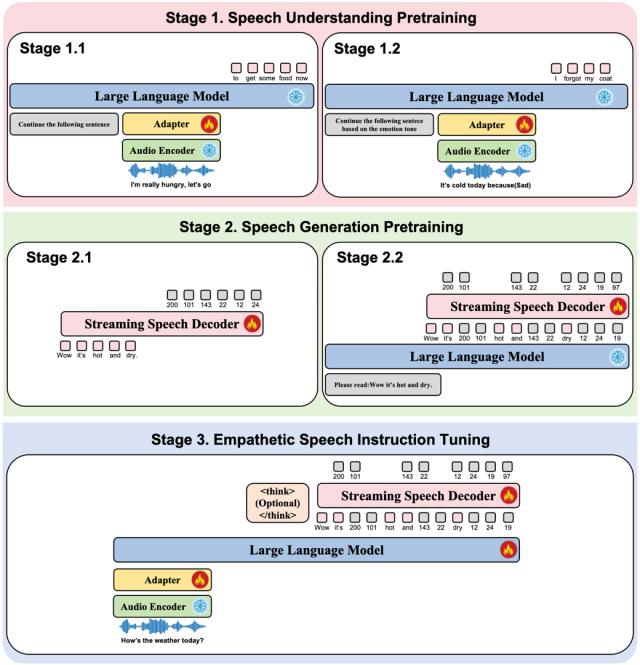
** △图 3 OpenS2S 训练过程示意图实验结果
端到端语音到语音共情交互相对难以评测,按照两阶段的方式,先进行语音到文本的评测,再展示语音到语音的共情交互样例。
语音到文本评测能够验证模型的语音指令遵循能力、语义和情感理解能力。在语音到文本的交互能力评估中,OpenS2S 在 VoiceBench 的四个子集上取得了优异成绩,其表现仅次于 Kimi-Audio(基于超大规模语音数据训练),优于其他所有模型。
这表明 OpenS2S 拥有强大的语音交互能力,能够高效理解用户的语音指令输入。此外,在 URO-Bench 的共情评估子集上,尽管训练数据量远少于现有最先进模型,OpenS2S 依然取得了很好的表现。
这不仅验证了 OpenS2S 的共情交互能力,也充分体现了其创新共情语音对话数据生成方法的高质量和有效性。
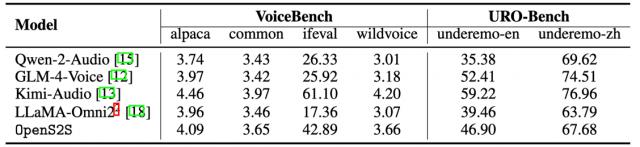
△表 2 OpenS2S 与其他模型在语音到文本交互基准测试中的性能对比。
在 GitHub 页面上还展示了若干语音到语音的共情对话样例。从例子中可以深切感受到模型对于用户的精准理解和共情能力。
论文地址:https://arxiv.org/pdf/2507.05177
Demo 样例地址:https://casia-lm.github.io/OpenS2S
代码地址:https://github.com/CASIA-LM/OpenS2S
数据地址:https://huggingface.co/datasets/CASIA-LM/OpenS2S_Datasets
模型地址:https://huggingface.co/CASIA-LM/OpenS2S
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
专属 AI 产品从业者的实名社群,只聊 AI 产品最落地的真问题 扫码添加小助手,发送「姓名 + 公司 + 职位」申请入群~
进群后,你将直接获得:
� � 最新最专业的 AI 产品信息及分析 � �
� � 不定期发放的热门产品内测码 � �
� � 内部专属内容与专业讨论 � �
� � 点亮星标 � �
科技前沿进展每日见博牛配资
淘配网平台提示:文章来自网络,不代表本站观点。
相关文章


沪深京指数
热点资讯
